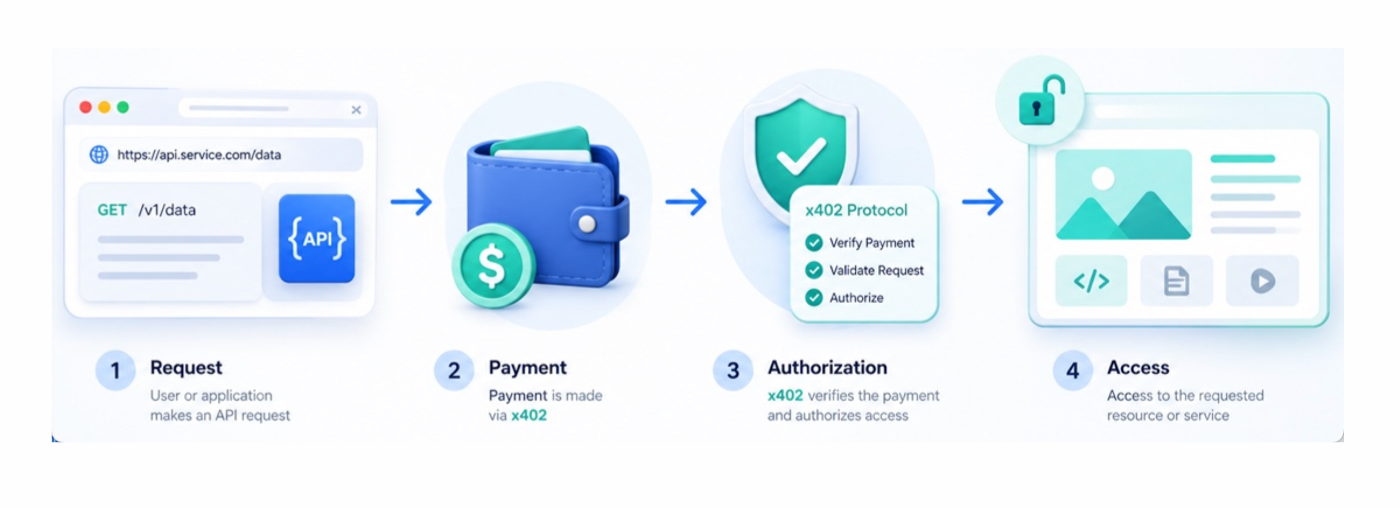
Safeguarding Your Digital Wealth
Cryptocurrency represents a rapidly growing class of digital assets. And actually, as Decentralized Finance (DeFi) gets more mainstream, I’m not even sure the original term “crypto” will even apply for much longer. Either way, more folks have Bitcoin, Ethereum, stablecoins, NFTs, and self-custodied wallets. Any might hold substantial value but behave very differently from traditional property in estate planning. Unlike bank accounts or stocks with named beneficiaries and institutional custodians, crypto relies entirely on private keys, seed phrases, and blockchain addresses. If using a more mainstream centralized exchange as a custodied solution, things might possibly work similarly to a typical brokerage firm. For everything else though? Without proper planning, these assets can become permanently inaccessible upon the owner’s death or incapacity, turning theoretical inheritance into real-world loss. While there’s all kinds of pros and cons we could talk about regarding truly self-sovereign control of your assets, one of the obvious ones goes beyond “Be more careful with your pass code info.” It’s that you can make it so secure, even you or your family can never get to it again.
[Read more…]