Safety Critical Applications Planning, Design and Development Checklist
In Part 1 I covered some aspects of what constitutes Mission Critical and Safety Critical systems, as well as some high level general concerns. Here, I’m going to provide a simple checklist for these types of products, followed by more detailed explanations of each of the checklist line items.
Suggested Checklist for Mission / Safety Critical Products
The following list may seem appropriate for any type of development work. But see the more detailed explanations below to understand how they’re special for Safety Critical issues.
- Have a culture of safety
- Budget Appropriately
- Assess level of rigor needed
- Choose appropriate project methodology
- Assess Risk
- Get to the real, actual users, somehow
- Re-think how you think about Design
- Account for user types, training and skill levels
- Create easily trackable and auditable systems
- Consider Architectural Implications
- Plan for potential failure – Communications and Fix Plans
- After launch validation
So now let’s go just a bit more in depth for these areas. As with Part 1, this list covers the basic concerns and you can just stop here if you like. Thanks for stopping by. Or… Read on for details.
Have a Culture of Safety
However hard we try, sometimes bad things will happen. This is obvious enough. For years now, I’ve been a volunteer Emergency Medical Technician with a local rescue squad. You never know whom you might end up treating on a call. But in doing this work, I quickly came to believe that no matter who it is, no matter their issue, their history, their circumstances, they should be treated as if they were one of my own family members or friends. Why? Because the difference between me being ok riding up on a fire truck and them being sick or injured is mostly just a simple lucky accident. Yes, our actions control a lot of our circumstance. But so does just dumb luck. If you work in emergency services, (career or volunteer), long enough, you come to realize this. And how would I want myself or a family member treated?

When building applications involving safety critical issues, I believe we should be thinking the same way about our users. Because any failures, as product people, can potentially hurt others. If we give ourselves a standard of care beyond just getting some feature or another out to market, perhaps we can achieve a level of quality appropriate to such critical applications. Maybe your organization already has this. But I’m throwing this out there as the question to ask… “Is what you’re building something you’d trust your life or your family or friends’ lives with?” If the answer is anything short of a confident “Yes, of course,” then some adjustments are probably in order. If the obvious moral issues aren’t enough to convince you, consider yet another question. “If you were on the witness stand testifying about your product after someone was negatively impacted, would you be able to honestly say you acted with all appropriate due diligence?”
Budget Appropriately

Safety Critical systems will likely require higher levels of upfront effort than others. Besides familiarity with any existing regulatory environments, (and possibly staff certifications), you may need external testing, longer quality assurance testing cycles in general, and an overall longer time to market than a similar product might if it had no safety critical aspects.
See Also:
Managing technology development for safety-critical systems
Assess level of rigor needed
- What safety level is needed in your case? Do you need to meet a formally defined level, such as a Safety Integrity Level?
- Are there certification standards you must meet? IEC? ANSI? Others? What are they?
- If there are no certification standards, should there be? Should you be crafting them?
- Craft your product as if you or a family member’s life depended on it
See Also:
Example standards:
ISO 14971:2007 Medical devices — Application of risk management to medical devices
IEC 60601-1-8:2006 Medical electrical equipment — Part 1-8: General requirements for basic safety and essential performance
ISO 26262-1:2011 Road vehicles — Functional safety — Part 1
Choose appropriate project methodology
There is nothing inherently right or wrong about any particular project methodology. Traditional Waterfall can absolutely work just fine for certain project types. And Agile methods, with Scrum and Kanban being the best known, are certainly useful in a great many cases. And there’s nothing wrong with combining these methods, or using them for various aspects of creation.

Perhaps a key distinction between Mission / Safety Critical applications vs. others is the depth of need for planning and discovery. It is possible to use Agile methods to great effect during the build phase of a project, but having done extensive discovery and high level design work prior.
As well, it might be the case that even for the build phase that traditional Waterfall methods are most appropriate. An interesting trend over time in Agile has been the layering in of higher level planning tools, from more dependency linkages to roadmapping and Scaled Agile. Part of this – I personally believe – is due to some of the non-trivial lacking in early – and still many current – Agile tools and methods when it comes to complicated dependencies.
One thing, (well, two things actually), that traditional Waterfall project methodology handles well are Work Breakdown Structures and task dependencies; such as start-to-start tasks, start-to-finish, and so on. Agile, which is meant to be somewhat faster on its feet, tries hard to inherently avoid such things in the first place, in an effort to simplify. That’s great. As long as the world complies. But when real world systems and dependencies might be inherently more coupled, it might make sense to use tools better suited to such efforts.
There is a large Body of Knowledge around traditional project management that might make it most amenable to projects with deep interdependencies.
If choosing Agile methods, that’s of course fine. You’re likely doing so in an attempt to use the benefits of such modern methods, which include flexibility and often speed. You may, however, need to customize your flow a bit. Minimally, for example, you will likely need to account for something like regulatory documentation, whereas with pure Agile, you may have just documented in code; if at all. One of the core tenets of the Agile Manifesto is, “Working software over comprehensive documentation.” I’m fairly certain sending this tidbit to the FDA won’t quite cut it if your product requires extensive documentation as part of its approval process.
Some may choose the V Model as well, for Validation and Verification and this can possibly be layered on – as a testing methodology – to either Waterfall or Agile. Remember always; besides regulatory requirements, there are no Methodology Police. (Or perhaps there are, but they’re limited to arguing on Reddit and such.) There is no law regarding what product, project or systems tools you use to get to your goals. (There are, however, laws regarding gross negligence and misconduct.) Craft a methodology that works for your product, your market and your team. Remember that part of the point of Agile is early testing for market viability. But in the case of Safety Critical systems, we want early testing for the sake of pure safety alone… are things actually working as they’re supposed to?
See Also:
V Model Software Development Life Cycle
Agile Development of Safety-Critical Software for Machinery
Assess & Manage Risk
Consider performing formal risk analysis for your product(s). In Part 1, we discussed planning and use of things like Fault Tree Analysis. Links to such resources are repeated in the See Also section just below. If using a product like Jira for project management, you may want to look into add-ons like SoftComply Risk Manager. (Note: I have not used this product and so cannot personally attest to its usefulness, however, I do see that they integrate with Confluence as well. And I am a big fan of coupling Jira with Confluence for extending documentation in a fairly fast and lightweight way that integrates with Jira.)
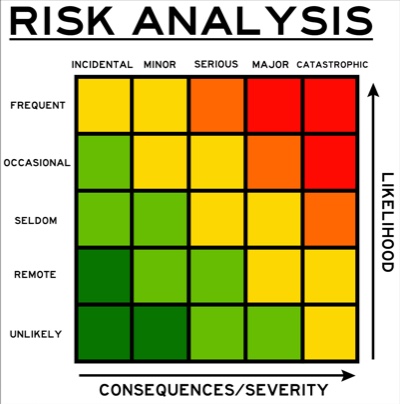
There are other risk analysis methods besides Fault Tree Analysis. You can consider using…
- Fault Tree Analysis
- Root Cause Analysis (which often uses some kind of tree style.)
- Why-Because Analysis
Let’s talk about risk types for a moment. Once upon a time, former Defense Secretary Donald Rumsfeld publicly talked about various types of risk. He talked about things like known unknowns and unknowns, etc. and subsequent to that, some media outlets and comedians just mocked him for how this all sounded. Because it does sound kind of funny. And yet, this was unfortunate. Because regardless of political leanings, what he was saying was quite simply some well known risk considerations. We should all consider the following types of risks:
- Known Things: We can know things like the tensile strength of a properly built material, or that certain agreed facts are true; such as simple math.
- Known Unknowns: We can be aware of things that are true, even if we’re not sure exactly what they are or when they might occur. For example, we can know that accidental fire is going to occur. OK, maybe it won’t ever. But as a practical matter… we can be sure enough that it will that we can claim to know it. What we don’t know is exactly where or when. But insurance, fire department placement, etc. all happens based on what we think, (through predictive math), might be probably likely.
- Unknown Unknowns: Yes, you got it… Aliens. The world shattering asteroid, (though this might actually be a known unknown… otherwise we wouldn’t be paying for and trying to build detection and interdiction capabilities.)
- Unknown Knowns: These are perhaps the most dangerous. These are things we think we know, but we really don’t. Or rather, we might ‘mostly know’ them, but our understanding is just incomplete. For example, perhaps we thought we designed that spaceship hatch just right, or the re-entry plan, but someone else, (a vendor, contractor, company, whomever), used the metric system when we used imperial units.
How do we deal with these various risk types? To start with, the first thing to do is just think about them in the first place. That alone can go a long way towards discovery. Some might argue that in some cases we can move or buy off the risk. That is, we can buy insurance. But our point here is really how to avoid trouble; not just buy it away.
See Also:
ISO 14971:2007 Medical devices — Application of risk management to medical devices
Repeated from Part 1 Planning Section.
Fault tree analysis
Root Cause Analysis: Different Techniques with One Goal
Root Cause Analysis
Why–because analysis
The Why-Because Analysis Homepage
Safety-Critical Operating Systems
A Methodology for Safety Critical Software Systems Planning
Making AI ready for safety-critical applications
Planning for safety (from Project Management Institute (PMI), Bonyuet, D. (2001). Planning for safety. PM Network, 15(10), 49–51)
Fault Tree Analysis FTA Explained With Example Calculation (4:08 Video)
Fault Tree Analysis Explained with Examples – Simplest Explanation Ever (12:34 Video)
Get to the real, actual users, somehow

One of the larger challenges for product and design people is to have good access to users for early discovery and ongoing product testing. There’s obvious day-to-day challenges to this; simple costs, coordinating schedules, and so on. But there’s a much more challenging issue when the products you’re building are something like B2B2C or Something2Something2SomeoneElse. The challenges here are at least threefold:
- It’s just harder to coordinate and get access to end user cohorts when going through an additional channel. That is, rather than selecting a valid sample from your own customers, or recruiting through a research agency, you’re going through a client or government agency or… some additional party.
- Your user is not your customer. When the buyer of your product, and your primary contacts are with your paying customer and not your actual end users, there is a lot more risk. Examples abound. Corporate procurement software is sold to finance personnel. (Ask vendors of large corporations how much they enjoy using imposed procurement systems of their corporate clients; how much it costs them in time and effort due to challenging software.) Healthcare is practically an object lesson in this. While procurement teams are getting better and including more stakeholders, everything from admin software to healthcare records are purchased by corporate, but used by people who often outright hate the software. Partly because a lot of the software is designed to really manage accounting issues more than healthcare. Or to build statistical models. Or whatever. Meanwhile, the Doctor or Nurse just wants to quickly document a care plan or something and get back to actually treating patients. And while abject dislike by users may – or should be – some concern, it’s when such issues cause actual harm we run into more obviously serious problems. Of course, sometimes harm is more subtle. E.g., on a long term basis, collecting data from hospital systems might help patients; but excessive time by medical personnel using systems rather than caring for patients is a negative. Where’s the balance? We certainly haven’t found it. And we really can’t just discount the emotional toll that the frustration from using such systems can bring. Over time, that can wear on caregivers.
- While data informed design is good, consumer ethnography is also a potentially eye-opening approach. It can be a non-trivial expense to travel to and embed into customers’ work and personal lives. But if possible, this level of observation – along with other data sources – can provide insights possibly not achievable through any other means. This level or research is becoming more desirable, but still relatively rare. When product, design and development are several steps removed from users, it can be challenging to do this level of discovery.
Consider a 911 dispatcher using Computer Aided Dispatch (CAD) system who is dealing with multiple calls. She’s taking calls while also furiously typing codes into various systems. Her keystrokes are not just keeping records; they’re being transmitted to mobile data terminals of responding units. Even just a few extra keystrokes risks slowdowns in throughput, potential errors, and user task saturation if there’s a need to go back and clear a mistake. If you aren’t including these end users in your discovery and testing process, how will you know about these issues? About what shortcuts they could use? About how to populate typeahead text tools with the codes particular to that venue? Are you accounting for exceptions? Maybe the CAD system recommends responding units “closest to the pin,” but the user dispatcher has reason to override this. How hard is that going to be? How much time? If the only people you get to talk to are the management at agencies, you may miss something. Or if you only gather data via sales teams that talk to management who talk to the actual users, (sometimes), chances are you’re going to have some line drops. This wasn’t a hypothetical by the way; this last example was based on a recent chat with an emergency services dispatcher. And while this kind of longer chain to get to the users is generally bad, it’s also not meant to be a dig on your sales team. Your salespeople can, (and should), be your major ally in these efforts. Good ones are deeply knowledgeable about their clients’ needs, competition and more. Still, if you really own the product, you need to be as close to the people actually using the software as you can be.
That was just one more obvious example to illustrate the issue of getting up close and personal with actual system users. Or those impacted by input needs or output results. The lesson should be clear enough. When product and design are several steps away from actual users, chances increase that critically important items will be missed. Often, these may be the tiniest and seemingly all but insignificant issues. But they can matter. And in fields where time is critical, that can be an issue.
Some other examples; there’s a great deal of automated production processes that depend on control units dispensing products in the correct amounts at the correct time for the correct conditions. For example, ever see a cement truck spinning its contents around and it heads down the road? Well, that driver’s load is a perishable commodity. Cement mix needs to be done according to ambient conditions, (temperature, humidity, etc.), and for particular project needs, (strength, cure time, etc), and then has a limited time to reach its destination before it’s no longer usable for the task. If you’re working on an end-to-end order management system for this type of product, you’d best be able to get to everyone along this chain. Any breakdown means expensive failure. And then there’s just about any process controller in all manner of chemical production plants.
Insert your own examples here. There are likely millions.
See Also:
Process Control in Chemical Plant
The CEO as ultimate end-user ethnographer Leading the way to understanding customers’ human experience
What is ethnography and how does it aid customer understanding?
Re-think how you think about Design
Let’s talk Design for a little while.
Design always exists in your product in some form. Your product presents itself to the world one way or the other, with intentionality in its presentations or just how it’s slapped together. Your choice. And that’s part of the point here, it is your choice. Budget limitations notwithstanding, effort you allocate to design is likely well spent. (And this covers everything from actual product interaction through training materials, help systems and so on.)

Practitioners working in contemporary technology creation generally have a solid depth of respect for those tasks we think of as design related. Not always. But increasingly, it’s well understood that good design isn’t just about something that looks pretty, but can be strategic and very much matter to top and bottom lines. It’s just… often that’s hard to quantify. Part of the challenge when considering value of design is that there’s so many aspects. At a surface level, sure… design is just “how it looks.” Maybe we just call that User Interface (UI) and call it a day. That alone matters of course. And then we have how it works and how people interact with things, and even how they feel about it, which we generally call User Experience (UX). A solid UX person is likely well informed about not only design, but behavioral psychology and similar. Next we have Information Architecture (IA). Uh oh. Where do we put this? Does it go before or after UI / UX or alongside? IA may be technical in that it can inform what we can do at all behind the scenes, (e.g., faceted meta data may be necessary to drive certain search functions). IA can manifest at surface level since the practice encompasses everything from taxonomy presentation to labels, etc. and how people understand depth vs. breadth, how to present to search or browse oriented users, and so on. When we think about the whole picture, many have taken to calling the whole package of all of these aspects as User Interaction Design (IxD).
These labels for varying aspects of design seem to be still evolving. And there’s mostly no bright lines separating them. It might be possible to break down certain tasks clearly into some of these different roles, but as a practical matter, that’s not really even useful given that at most organizations, it might be just one person doing all of them. In a perfect world, you’d have budget and headcount for all of them if your product calls for it. If not, at the very least you know enough when to bring on a consultant temporarily to backfill for some of this if necessary.

When it comes to crafting the actual product itself, you would do well to make sure design staff is early in on whatever your up to; customer discovery, early planning, etc. This is most often just as true – or perhaps more so – for your technology team. After all, it’s the engineering team – and only the engineering team – that can make things go. As has been said, “those who control production, control the world.” And yet, it’s this kind of thinking that probably incurs the most dangerous risk of potential failure. Everyone wants to be in the proverbial room for all choices. While this maybe isn’t always practicable, it should be a goal. (And this is where some of the team aspects of methodologies like Scrum likely excel over Waterfall.) The point here is that for mission and safety critical applications, designers and design thinking in general might catch critical issues otherwise missed by development teams. Good IxD personnel aren’t just pushing some pixels around the screen. They can discover and solve both major and minor issues that are going to be fundamental to your product’s success. But only if they’re deployed properly and given the access to tools and info they need.
The critical thing to consider about design from the Product Manager’s perspective is this: If you are still thinking of design in terms of just how something looks, the colors, fonts, or maybe buttons and switches, then you are probably dangerously out of touch with what modern design means and can do for your product. Once upon a time, interaction designers might have been thought of in terms of being Photoshop Drones kicking out some graphic assets needed for production. And once upon time, that was maybe true and even perfectly appropriate for the tasks at hand. Now? Design – in some aspect or another – is core to everything in your product.
When it comes to features, and design, you may have heard the somewhat cliched discussion about how “you are not your user” and the dangers of thinking this way. At the same time, user empathy is increasingly seen as a critical emotionally intelligent value for getting to user understanding. The path through any ambiguity in this regard for safety critical applications is to go back to intentionality and run your risk analysis checklists for interactions you’re considering. And do so with intellectual honesty. Steve Jobs is hailed as one of the greatest product ideation folks of all time. I think of him as an “intuitive marketer.” And yet, it all wasn’t just from his gut, and he certainly wasn’t always right. Or maybe not always just right at the right time. An early personal digital assistant, the Newton, failed miserably in the early 1990s, only to see various other devices from the Palm Pilot and so on to rise later. Of course, Steve arguably had the last word with the iPhone. (This was an example of the technical environment needing to catch up to his vision.) However, we also have him not putting a forward delete key on early Mac keyboards. While you can do it with a function/modifier key, it’s not – or wasn’t – a separate key as on standard PC keyboards. Supposedly, (though it’s hard to know the truth in Apple lore here), there was some aspect of this that Steve Jobs didn’t like, so it wasn’t put on the keyboard. A simple thing. But fundamentally has annoyed Mac users for years. Has this killed anyone? Probably not. But how much lost productivity until people learn the workarounds? And some never do. (How many people do you know who only use the mouse to cut / paste and never learned the simple keyboard shortcuts? They’re out there.) And while some may respect Jobs’ commitment to holistic medicine, others might argue it was no small degree of arrogance that killed him when modern medicine could very well have extended his life or even cured him of his fatal illness. Among the things I find interesting about Jobs is that as intuitive as he was, he was certainly also intentional. (Seek out the many videos where he discusses product.) And yet, my final lessons from him are simple: 1) Most of us are not Steve Jobs, though we can learn from him, 2) While confidence is good, arrogance is bad and when that arrogance is with a decision-maker, it can be really bad, 3) Lean towards intentionality and verify assumptions as early as possible. We will always have to make choices with imperfect information. But if we at least take a little bit of time to even think through implications and our original intention, we can ideally avoid the worst scenario outcomes. Obviously, our goals are the best outcomes, but for safety critical, avoiding worst outcomes must be highest priority.
See Also:
Understanding the World of Digital Design: UX, UI, IA, and IxD Explained
UX vs UI vs IA vs IxD : 4 Confusing Digital Design Terms Defined
What Is Information Architecture in UX Design?
An Excellent Beginner’s Guide to Information Architecture
Account for user types, training and skill levels
Assuming you have some user persona information, you should have some idea of for whom you are building products. Are these highly educated professionals using advanced tools? Or are these barely literate adults? Non-native English speakers? Age, gender, racial and disability issues can all significantly impact how a user might interact with a product.
Users of various products may also have significantly different training levels and needs. Among the basic differences between users includes what level of exposure they’re going to have to your products. And of course, the nature of the product itself. An emergency response vehicle driver is likely using their Mobile Data Terminal system all the time. Even small idiosyncrasies in the system may not be ideal, but might not be that big a deal because users will acclimate to them. And consider Air Traffic Control systems. The interface may be downright cryptic to those uninitiated, but they’re designed for speed and lack of clutter based on people being trained for months on their proper usage. Other products, such as consumer in-vehicle entertainment systems, kitchen devices, etc. may be items that people will get used to over time and are willing to learn – just a little – in terms of how to use. And then – on the other hand – there’s devices people may pick up only intermittently, such as a more rarely used medical instrument and such. The less training anticipated and the less frequently used, the more important it may be to rely on recognition vs. recall design and training principles due to skill decay over time.

Recognition vs. Recall is a fundamental concept in User Interface (UI) and User Experience (UX) design. The basic difference is that recognition is a response to a sensory cue and recall is the retrieval of information from memory without a cue. In many consumer products, it’s generally thought to be best to make sure recognition is a primary goal such that just about anyone can pick up a product and understand how to use it. To a large degree, this is the whole point of iconography. To this day we use mailboxes as an icon for email, even as email has grown to be less like physical mail. But optimizing recognition might not always make sense. Again, take the air traffic control systems example. You could make it ‘easy’ through a lot of means, but you’d almost by necessity reduce the critically required speed. There are ways to have it a little bit both ways. This is what shortcuts, (such as control key equivalents), are for.
It’s likely the case that some of the singularly most dangerous products in this regard are those that are used intermittently and potentially suffer from skill degradation. If you know you have this issue, you can perhaps account for it with training and re-certification requirements or alternative interfaces or all of this and more.
The point here is you need to carefully assess the task(s) at hand, the users and their training requirements in your design. If it turns out to be the case that your system requires months of costly training prior to competent certification of an operator, then so be it. Just make your choices explicitly thought out.
See Also:
Memory Recognition and Recall in User Interfaces
The Differences Between Recall and Recognition
Factors That Influence Skill Decay and Retention: A Quantitative Review and Analysis
Context-Dependent Decay of Motor Memories during Skill Acquisition
Create easily trackable and auditable systems
For Mission Critical systems, you will most often need to track data or audit data over time. This might be for actual product usage considerations, or long term regulatory record keeping.

Commercial aircraft carry the infamous black boxes. (Which, as you would think, are usually more bright orange than black.) These impact force-resistant devices record cockpit voice and aircraft data and have been key to making aviation among the safest ways to travel; albeit at great cost. It might be even better to get all this data streamed real time rather than only available after a tragic accident. And in fact, folks are working on this. Wouldn’t it be better if that device only had to store maybe an hour of emergency data vs. potentially much more for long flights? And wouldn’t it be great if systems somewhere were able to analyze streaming data for potential anomalies and predict potential upcoming problems?
Your product may not have the same needs as a commercial airliner. But you may want or need to have some audit capability for quality assurance, adverse event investigation, and possibly for regulatory requirements. Let’s consider an example from Remote Patient Monitoring (RPM). Often, data will be collected from a variety of devices that could be coming in via a push to an API, or polling of an external data set, and the transmission may be WiFi, Bluetooth, Bluetooth to WiFi, Cellular network, and others; possibly several methods in use at the same time. When the data comes ‘in’ to wherever it’s being delivered, it’s likely be used for calculations, possibly end user display(s), and likely some form of alerting. But what if something goes wrong? There’s often an immediate need to solve the problem and there may be – unfortunately – a need to investigate an adverse event after the fact. Have you architected for this? Is your data being sent directly to live systems? Or are you doing some form of Extract, Transform, Load (ETL) process first? If doing ETL, are you hanging on to the original data? Are you time stamping in a reliable way? Are you including meta data such as device type, when it was put online, the vendor(s), and so on? (This might allow you to do quality and longevity checks of devices, networks, and so on.) Whatever your situation, chances are you have some tracking and auditing needs. These likely imply some work on the database schema side and consideration on the data storage side. (E.g., live use data needs to be in an online system where as historical data may move into a less costly data warehouse.)
Data Management is likely required for functional requirements of your product. But possibly also non-functional needs. All needs to be dealt with. Could you potentially launch an MVP without completing such work? Sure. Would this be wise? That’s your assessment to make.
You will also need to make sure any vendors you are using have compliant components.
See Also:
How do SBOMs Support Safety Critical Software?
Consider Architectural Implications
Much of modern development happens in cloud based architectures. And yet, even within these structures, there are a variety of considerations. Are there availability zones that are preferable – or required – for performance? Or will differing zones be needed primarily for backup only. What kind of backup? Live failover to secondary or even tertiary systems? Do those systems need current state(s) of information from external data sources?
- Will it be easiest / best to use containerization methods for deployment and continuous integration?
- What are exposures to external services and APIs? Are there multiple sources for data? If not, do you have systems reliability monitors in place? And what are the backup plans for any third party ‘heartbeat’ check software?
See Also:
Strategy To Deploy A Highly Available, Mission-Critical Application On Cloud
Application platform considerations for mission-critical workloads on Azure
Plan for potential failure – Communication and Fix Plan
Assume potential failure. And if at all possible, design for graceful degradation with backups.
Your specific system flows should of course account for known risks. If data from an airspeed management system appears to be missing or false, then that should obviously alert itself visually and perhaps aurally via systems and yet, fail only that data point, not an entire flight system display. When an automobile emissions sensor goes bad, notating this is likely better than disabling the entire engine, etc. etc.
Practically by definition, some failures will occur from wholly unforeseen circumstances. In some cases, it may be a failure mode that falls under the category “should have known.” But even if assuming not, the point is to have some generic plans as well. How will you communicate an issue to your customers / users? What is the general plan to deploy support personnel?
After launch validation
In some ways, this can arguably fall under the category of auditing. After you launch your product, if at all possible it makes sense to test with non-critical conditions present. This might not be possible, but if it is, it should be part of your launch planning.
Conclusion
This has been a long tour through a variety of items of concern for Safety Critical systems. It’s likely not a fully exhaustive list. Your particular product may require additional line items. If I’ve missed some large categories here, please reach out and let me know.
Additional Readings
Checklist for Safety Critical Systems
Towards Safety Assessment Checklist for Safety-critical Systems
Characteristics of Safety Critical Software (In regard to ICBMs. An interesting perspective)
Safety critical software ground rules
Best Practices for Developing Safety-Critical System Software Requirements