TL;DR
Following are some things I’ve been coming across as I work, (and play), with some of our new tools. These days, whatever your level in Product, chances are you’re building or at least looking at something involving Agentic workflows or AI.
Given the increasing ease of use of new tools, you’re probably working directly with them. Hint: Even if you’re a CPO or VP, if you’re not getting your hands dirty, you’re similar to the CEOs as recently as the 1990s who were proud of the fact that they didn’t use email. Is that really the box where you’d like to constrain yourself? As with so many things, you don’t likely need to be an expert here. You just need to understand what the tools in your box can do and certainly some of the risks we face. Whether as Individual Contributor (IC), or senior manager, there’s risks and basic practices you need to have on your checklist that should be table stakes. Many of us now build with Low Code No Code or are VibeCoding our way to MVPs. Great. These tools are awesome for prototyping. For production though?
Watch out.
Stop here and just ponder that thought if you like. For details… read on. (Note that some of the upcoming examples are for any product person, whereas others are for more technical PMs or their developer partners. Regardless, they should give you a sense of what kinds of things you need to check off your list.)
There are plenty of articles on AI risks. This is my take based on what I’ve been coming across lately, so I thought I’d offer another perspective. There will be a little tech in here, but not much. It’s the age-old question, how much tech does product need to know. The unsatisfying answer is always, “it depends.” We’ll go a little deep in a couple of areas here just to illustrate an item or two, but just for the purpose of example. We just need to be aware of some things so as to account for them if we own schedules or P&Ls and to work well with our developer counterparts. We’ll start with an outline, then summarize each issue.
Risk Category Outline for Agentic and AI
Part 1: Exciting Details Below
- Financial / Token Usage
- P&L
- Fraud
- Dependencies / Infrastructure Ops
- Workflow
- API
- Scrape / Oracle Endpoints
- Crypto
Part 2: Details on the following sections will be in a follow-up article
- Model and Output Risks
- Incorrect Answers
- Dangerous Answers
- Intentional Jailbreak
- Bias / Fairness
- Security, Governance, Risk & Compliance (GRC)
- Security (Beyond Fraud)
- Privacy / Data Governance
- Regulatory / Compliance
- Ethical / Societal Issues
Full treatment could be a book length treatment for each item. I’m just going to lay out basics so you have an understanding of the core risks and their sources, plus potential mitigations.
Financial / Token Usage: P&L
Whether using GPTs or Agents, you or your finance counterpart will need to work on the P&L. Your product’s profit and loss may end up with more on the cost side tied to AI usage than is typical for other tools. It’s one thing to account for things like basic API usage, such as database usage or payment gateway transactions. These are usually relatively easy to account for as fixed or variable costs and get covered in your financial model. However, AI can be different in terms of variable costs. Whether cloud or on prem solutions, think of “tokens” as units AI models charge for. The concern is runaway costs. Agentic systems (AI that acts autonomously, like a virtual assistant handling tasks end-to-end) can loop through actions unpredictably, spiking token usage and blowing your budget. This means our shiny AI feature could turn into a financial hole if users trigger expensive chains of operations. It’s not just overall budget, there may be rate limits. (I had a situation where a tool I was using was within budget, but a usage spike came close to exceeding other limits. It took awhile to sort out where and why.)
Mitigation starts with budgeting: set limits on token spend per user/session via API controls, monitor usage in real-time with dashboards, and design workflows to favor efficiency. E.g., cache common responses or use cheaper models for simple tasks. Definitely test scenarios in staging to predict costs before launch. (They’ll maybe be wrong, but ideally not by much.) Tokenomics may be thought of as a crypto term, but AI certainly has Token Economics of its own. (See Why AI Usage Costs Are Rising: The Token Economics Challenge for Enterprise Applications and The Hidden “Verbosity Tax” in AI: Why Per-Token Pricing Isn’t What It Seems and finally, The Overlooked Costs of Agentic AI.)
Are we generating enough more value to justify these costs? A fantastic new feature just isn’t viable if it’s going to put us out of business.
What Can You Do? Collaborate with finance to model AI costs in your P&L by forecasting token usage scenarios and consider setting tiered pricing for users to offset potential spikes if you can. Implement usage caps, ensuring features remain profitable without compromising user experience. This will likely take some iterations once you have a sense of real-world usage.
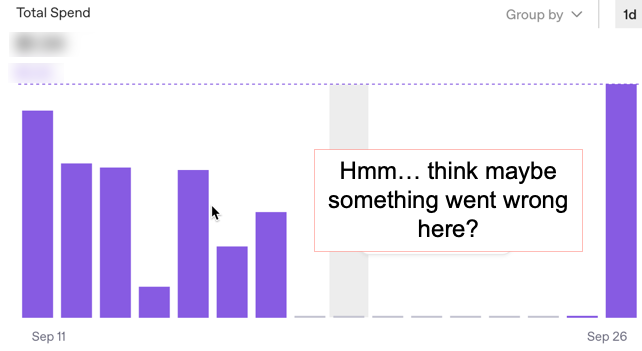
Financial / Token Usage: Fraud
If using external services and you leave a secret message or an API key open, your account is going to get drained. It’s just a matter of time before bad guy seeker ‘bots find your open API and burns your account down. Maybe someone typed your APIs or secrets into a GPT while troubleshooting and that somehow got exposed? Were you testing in the open with a Webhook that really should be obscured and rotated?
Fraud here means unauthorized access to your AI resources. You get both financial loss plus maybe reputational damage if it leaks that your security was lax.
What Can You Do? Treat this like guarding your company’s credit card: implement key rotation policies, use environment variables instead of hardcoding secrets, and enable multi-factor authentication. Audit logs for unusual activity and set up alerts for usage spikes. People have put keys in their apps, bad idea. And thousands of keys have been found in AI training data! This developer’s accidental posting of an API key to Github only cost tens of thousands. And yet, even high security firms like Coinbase can get hit for tens or hundreds of millions. But don’t worry. I’m sure your Low Code No Code AI assisted demo has its keys perfectly secure! In early testing, I used No Code AI to build a product, but didn’t fully trust it to host. So I saved it to GitHub and had it automatically deploy to a server with FTP. The problem was API calls. I had to test in the tool, but then change the keys to variables and put them in GitHub environment variables to keep them safer.
This is all really on the dev ops side. But to ensure mitigation, enforce team-wide protocols for secure key management, such as mandatory rotation schedules and training on avoiding public exposures, while integrating automated alerts for anomalous usage in dashboards. Audit repositories and use encrypted secret tools. No, you don’t want to be “that pm” annoying the hell out of your dev team leads by telling them their job. At the same time, this is an issue that easily falls into the “maybe not your job, but absolutely would also be your problem” category. So at least ask the right questions to make sure the issues are covered. Here’s a club you don’t want to join: 110+ of the Latest Data Breach Statistics to Know for 2026 & Beyond.

Dependencies: Workflow
Workflow dependencies are interconnected steps in your agentic system. The concern is brittleness: if one link fails, the whole process halts. This could mean high churn if your AI-powered feature flakes out.
What Can You Do? Map agentic workflows to identify failure points, then prioritize building redundancies and retries during sprint planning. (You might need to do this anyway to build “as built” models for various types of regulatory compliance or for desired certifications.) Request engineering exercises to simulate breakdowns, refining the product roadmap to include fallback features that maintain core functionality during disruptions. (I.e., are there ways to fail gracefully.)
Dependencies: API
API dependencies might be internal, but are often external interfaces your AI agents call on, like third-party services for data or processing. The risk is downtime or changes: if the API goes offline or alters its format without notice, your agents could fail spectacularly, leading to broken user experiences. Or maybe worse, incorrect outputs. We face the challenges of service interruptions eroding user trust and emergency fixes.
Here’s just one example. I use a WordPress site with a custom GPT with RAG for a medical community support site. The agentic workflow is managed with n8n. It would be simple to just call the API endpoints, but they’d be exposed. You really need to use Webhook Security with Token-Based Authentication or Secret Key Verification.
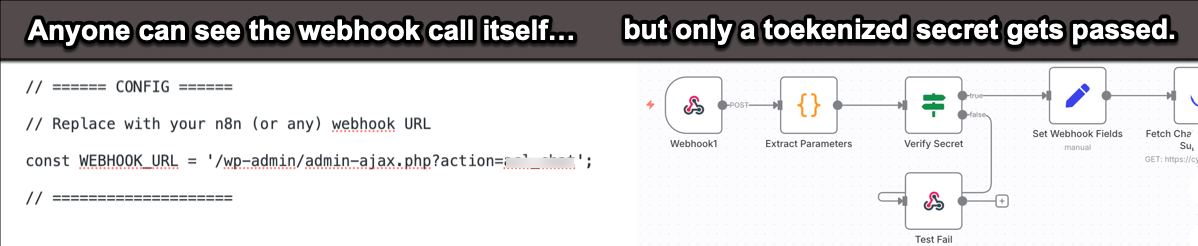
This could be hardened much further. There’s things like signature verifications, (to avoid payload tampering), timestamp validations, (to thwart replay attacks), IP Allow Lists, (restricts webhook access), rate limiting, (avoid DDos), and more. Am I doing all of these things for a little hobby site? No. Partly because I don’t really know how and partly because the risk isn’t that high since there’s rate limits set on my token usage anyway. Agentic providers get this. Among other things, LangChain recently added more advanced API controls with more granular role assignments to LangSmith.
However, I’m aware of these things because when working with anyone else on a real project, I need to make sure someone is on this. It might not be my checklist. But we as product folks need to be sure: “CTO has the security checklist.” And that either myself or an assigned PM has accounted for the time and effort. The point is, you need to assess the cost / risk / benefit of what you need to do because it’s still ‘your’ product.
Do you see the risk here in terms of some of the raw stupidity of some posts out there claiming You Can AI/Vibe/Etc. your product right to market in just days! Maybe. And you can also set yourself up for major risks. The NoLoVibe thing is awesome for prototyping and idea sharing. For production? Just think about it.
What Can You Do? Mitigate by choosing reliable providers with SLAs (service level agreements), implementing versioning to handle changes gracefully, and caching responses where possible. Build in monitoring tools to alert on API health, and have contingency plans like switching to alternative APIs seamlessly. Try to simplify what you really need. Try for observability. We’ve always had workflows. But with an increase in agentic flows, this could get away from us. What tools might our agents be selecting?
Dependencies: Database / Scrape / Oracle Endpoints
Do each and every endpoint your agents or AIs use have security on them and is that security happening in ways not visible to external AIs? Agents are sometimes just souped up workflows. But they may be making decisions as well. Let’s take a common use case of a database as an example.
Let’s jump into the exciting world of Row Level Security (RLS). (Not for long. We’re just going to breeze through it as an example.) This actually isn’t about RLS, but I’ll get to the main point soon. Here’s what some of it looks like in Supabase:
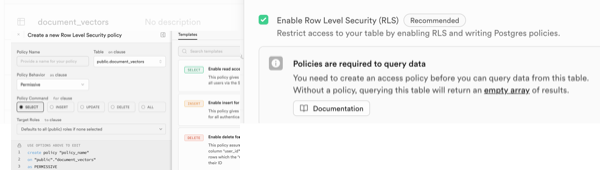
Do you have security set there? I’m not talking about the API itself, but below that at a table’s row level? Do you even need that? Row-level security (RLS) is a database security feature that restricts access to specific rows in a table based on the user’s identity, role, or other criteria defined by a policy. It provides an additional layer of security. This is part of what’s called Defense in Depth. Why it matters: Security is best implemented in multiple layers. If an API is compromised (e.g., due to a bug, misconfiguration, or stolen credentials), RLS acts as a safeguard at the database level to prevent unauthorized data access. Another benefit is regulatory. Regulations like GDPR, HIPAA, or SOC 2 often require strict data access controls.
Enough about RLS. The point was just to show how deep we can go in these areas. I’d said this really wasn’t about RLS. It’s not. The point is, what else is there? How many other little gotcha’s are out there that Low Code, No Code AI tools don’t necessarily cover?
These endpoints are sources your AI pulls from, like databases for internal data, scrapers for web content, or oracles for verified external info (e.g., blockchain price feeds). The concern is vulnerability: insecure endpoints could leak sensitive data or inject bad info, leading to privacy breaches or flawed AI decisions that harm users. This risks legal fines or product recalls if tainted data causes issues.
What Can You Do? For scrape and oracle endpoints, work with devs to implement layered security like RLS and encryption, while defining product requirements for independent monitoring workflows to ensure data integrity. Consider encryption for data both in transit and at rest. Include rollback mechanisms in your feature specs and schedule periodic audits to verify endpoint reliability, adjusting user-facing features based on quality check outcomes.
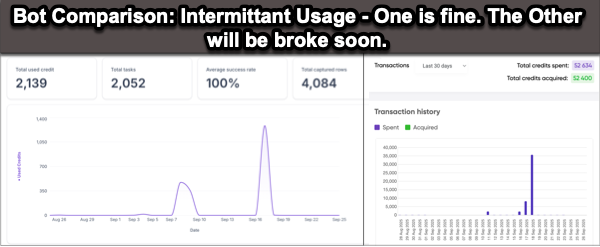
Also, watch the costs and burn down on any accounts. Here’s two ‘bots used in a product I’m involved with. One of them is fine. It’s intermittently used and mostly manual. The other one is on the edge of running out of tokens. If something were to hit this API repeatedly, it wouldn’t just be costly, it would break whatever that flow might be. This is part of a pre-production workflow, so they’re non-critical in terms of runtime. Still, serves as a good warning to have alerts set for approaching limits. And those alerts? They should probably not be going to the email of the person who quit three weeks ago.
Dependencies: Crypto
Are you doing things with Crypto and AI together? My, my… you are fully buzzword compliant, aren’t you?
Note that if some agent drains someone’s account and uses your service to do it, at some point, someone’s likely coming after you with a lawsuit. And it won’t matter if it’s not your fault at all. You may be the only available target. So you’ll likely be named in any malfeasance that passed through your pipelines. And of course, even if you get out of legal liability, you’ll be top of the tech news until something worse breaks.
Crypto dependencies involve integrating blockchain or digital assets into AI agents, like an AI that automates trades. The big risk is irreversible errors: AI mishandling crypto could lead to fund losses, with your product as the scapegoat in lawsuits even if indirectly involved. PMs should worry about liability exposure in this volatile space.
What Can You Do? If you are doing this within 2025, you are still in the bleeding edge tragically hip crowd. You may be a bit on your own in sorting out new threat surfaces, but perhaps starting with the usual rules applies.
Limit AI autonomy (e.g., require human confirmation for high-value actions), monitor for anomalies, and secure wallets with hardware keys. (LangChain just added Agent Middleware that includes Human-in-the-loop: features.) You might want to carry cyber insurance tailored to crypto risks. I can’t really know this, but common sense and history tells me bad guys will have scanners out looking opportunities, just as they do for open APIs. Crypto breaches against smart contracts aren’t new. Adding complexity here feels like it’s begging for attacks. The too-cool-for-school Decentralization crowd may not like this, but I’d actually be thinking if some centralization was ok here. It might undercut some blockchain value, but I’d be scared of irreversible errors. I’d rather be able to plug holes vs. unlimited ongoing losses, not to mention keep regulatory compliance. This may be a philosophical issue as much as technical when it comes to Web3, etc.
Why You’ll Still Be At Risk
You can do everything you possibly can as correct as you possibly can. And yet?
Right now, there are aspects of AI itself as well as the various rails that feed it that are essentially out of control. (That’s an opinion on my part, but it somewhat feels that way.) For specific use cases, (maybe linear or logistical models going against a constrained medical dataset), you’re quite likely to be ok. Even if slapping an LLM on the front of something like this for easier natural language querying, (sorry, “Prompting”), can likely be focused enough to be reasonably safe.
However, the more general your tool or offering though, the less likely any guardrails are going to be complete. Even as better tools are built to try to allow for more deterministic results and auditable observability, there will likely be holes. It’s likely the means to deal with these issues are backup workflows including everything from business insurance to crisis public relations planning, product usage limitations (by age or role or similar), and ability to quickly respond and adjust to any severe conditions that emerge. In terms of source content, major AI companies are signing deals with some content producers, but this is fairly uneven. At least, on the surface it seems like deals happen with those who are seen as potentially big and angry enough to present legal concerns. The rest? Well, that’s just the rest.
Where will you fit in all of this? It might be worth trying to draw that map so you can consider where you’ll need effort and what you can maybe mitigate or even ignore completely. At least for now.
Wrapping Up
Navigating the risks of agentic AI and workflows is in a lot of ways going to be more challenging than typical traditional risk management. There’s a lot of so-called “known unknowns” and likely some pure “unknowns.” The challenge is generally in being a lot more proactive. You need a blend of vigilance, technical safeguards, and strategic planning. Mostly, we’re really talking about mitigations, like cost controls, layered security, and ethical guardrails. However, no system is foolproof, especially with general-purpose tools where gaps persist. We’ll need to have a mindset of continuous improvement, backed by monitoring, testing, and crisis readiness, to ensure our products not only deliver value but also maintain trust and safety in a fast-evolving marketplace that likely will also have increased threat surface areas.
In Part 2, I’ll finish offering some details for the rest of the items in the outline.